Managing LLM Context Is a Knapsack Problem
Sun Jul 09 2023
LLMs can be more useful and less prone to hallucination when they’re able to read relevant documents, webpages, and prior conversations before responding to a new user question. Unfortunately, LLMs have a finite context length that can be quickly exceeded when asking it to read these external resources. So one must somehow decide which resources are worth asking the LLM to read, and it turns out this is a Knapsack problem.
Knapsack Overview
The Knapsack problem is a classic dynamic programming problem and is typically introduced with the following narrative:
A thief robbing a store finds N items. Item i is worth v[i] dollars and weighs w[i] pounds, where v[i] and w[i] are integers. The thief wants to take as valuable a load as possible, but can carry at most W pounds in his knapsack, for some integer W.
Which items should the thief steal?

The above is technically the 0-1 variant of the Knapsack problem because the thief can either steal either 0 of 1 copies of each item (and not multiple copies or fractional copies).
Deciding What To Show the LLM
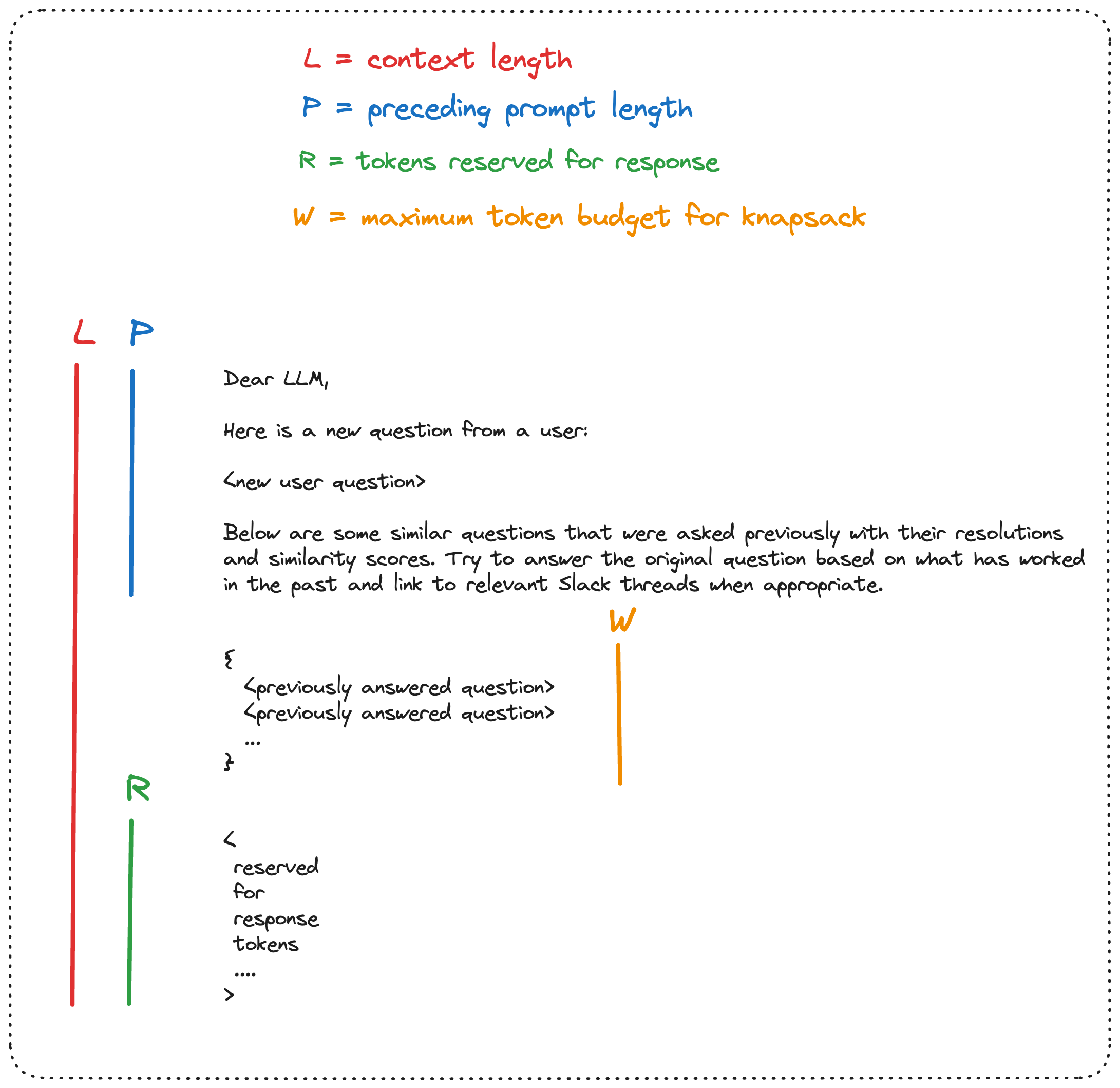
Let’s imagine you are using a LLM to answer a user question and you want it to read as many relevant documents as possible before responding. Each document costs the LLM a certain number of tokens to read which is w[i]. And each document has some value v[i] too, which can be computed in a variety of ways depending on your goals. For example, you could use embeddings and cosine similarity to score documents based on how semantically similar they are to the user’s new question. Maybe you also want to decrease the score of older documents since they’re more likely to contain outdated information.
Once each document has a known cost and value, we need to decide on our token budget W. The maximum value for W is equal to L - P - R, where L is the LLM’s context length, P is the length of the prompt preceding the selected documents, and R is the number of tokens reserved for the LLM’s response. Now you can plug all these inputs into Knapsack and you will be returned the selection of documents that are most worth reading given your budget.
Other Considerations
- You might instead want to use the greedy approximation solution to the Knapsack problem because it runs in O(N log N) and has a very simple strategy of first selecting items with the highest value:weight ratio. The dynamic programming solution runs in O(N * W) which is pseudo-polynomial but may be far more optimal in some cases.
- Sharding a document could be a viable strategy for dealing with documents that include irrelevant information. However, deciding how to split up a document while preserving it’s value seems like a non-trivial problem. Maybe the LLM itself could preprocess and summarize the documents beforehand?