SimpleDB: A Basic RDBMS Built From Scratch
Sun Jan 30 2022
My databases class at UCLA wasn’t very challenging so I never truly understood the internals of databases. This always bothered me so I vowed to build a simple database from scratch to learn the fundamentals. MIT's Database Systems course has their students implement a simple database from scratch and it provided me the perfect guidance in achieving my goal. The SimpleDB database I built has basic RDBMS features like a SQL query parser, transactions, and a query optimizer. This blog post provides an outline of SimpleDB's architecture and implementation.
Architecture
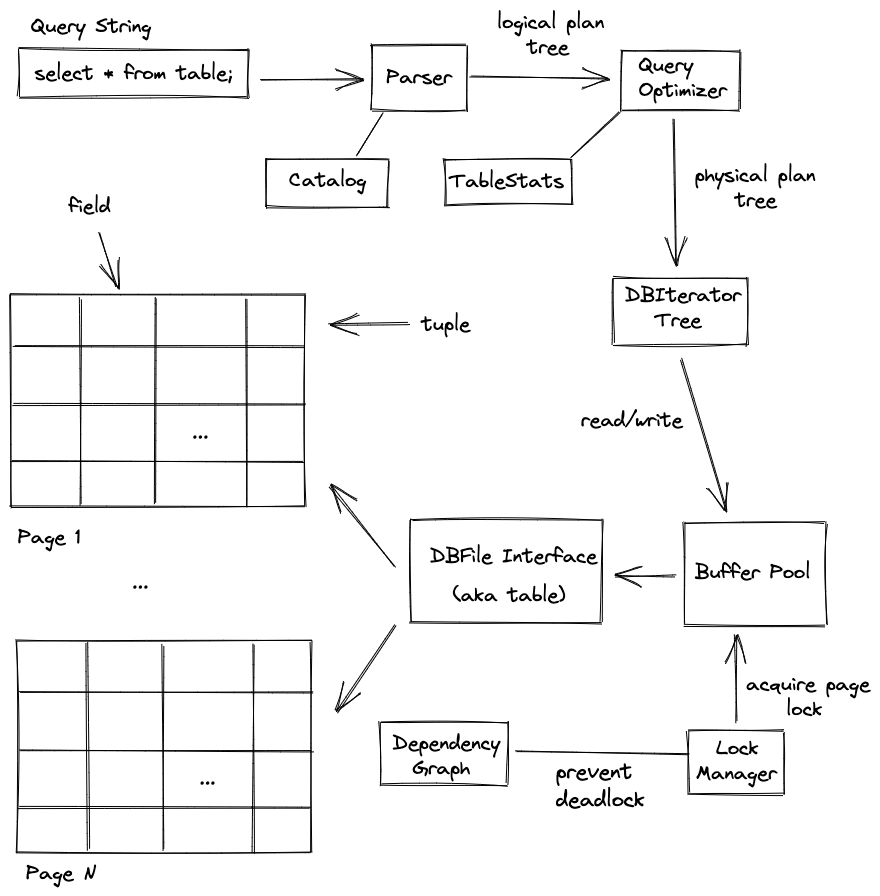
Data Storage and Access Methods
Database rows are referred to as tuples in SimpleDB. Each tuple has a set of fields which represent the column values for the given row. Currently the only supported field types are strings and integers. The current implementation also requires that all tuples with the same schema use the same number of bytes regardless of field values. Tuples are stored in pages, which are stored on disk. Pages belonging to the same table are grouped together under the same DbFile instance, which provides an interface to read/write pages and tuples to disk. Each database table is stored as a DbFile instance.
The Catalog singleton object manages adding new tables and viewing schemas and primary keys. The BufferPool singleton object manages all page access and modifications. Because BufferPool has a global view of all page accesses, it can cache frequently used pages in memory so that page fetches doesn't always go to disk. Once the BufferPool cache gets full, it will need to evict pages using some eviction algorithm. The BufferPool evicts pages using the no-steal algorithm to provide ACID transaction guarantees, which is discussed more in the Transactions section below.
Operators
The query parser takes a SQL query and converts it into a logical plan. This logical plan represents the SQL query as a tree of relational algebra operators. The query optimizer will then take this logical plan and convert it into a physical plan composed of physical DBIterator operators by applying equivalence rules and cost-based optimization.
The DBIterator physical operators are the actual primitives used to execute the query. Here is the list of physical operators currently supported by SimpleDB:
- Sequential Table Scans
- Insert
- Delete
- Order By
- Filter
- Project
- Aggregations
- Nested-Loop Joins
- Hash Joins
The DbIterator interface lets physical operators fetch tuples from their children using hasNext() and next(). These tuples flow starting from the leaves of physical plan tree to the root while undergoing transformations performed by intermediate operators. The leaf nodes of the physical plan tree are always going to be operators that read tuples from the buffer pool. After the tuples reach the root node, they are displayed to the user as query results.
Query Optimization
The query optimizer takes a logical plan as input and tries to convert it into the cheapest possible physical plan. In order to estimate the cost of a physical plan, we need statistics like table size and data skew. TableStats computes histograms for each column in a given table and these statistics are used to estimate selectivity, scan costs, and cardinality for a given physical plan. SimpleDB uses Selinger Optimization to determine the cheapest way to order multiple joins in a query. A naive solution to the NP-hard problem of ordering N joins would take time, but Selinger Optimization leverages dynamic programming to achieve time.
Transactions
Transactions provide ACID guarantees for SimpleDB queries. It should always seem like the operations in a transaction were executed as a single, indivisible action. Because transactions run in parallel, some form of locking is necessary to avoid data races between concurrently running transactions. SimpleDB uses strict 2PL for concurrency control and locks data at the page-level. LockManager provides support for both shared locks and exclusive locks to allow multiple readers to access the same data in parallel. Locks are grabbed when a page is fetched from BufferPool, and the page fetch function blocks until the page’s lock is acquired from LockManager. Blocking in this fashion runs the risk of deadlock, which is why SimpleDB also implements a DependencyGraph which detects deadlocks via topological sort. If fetching a page triggers a deadlock, the calling transaction will be aborted. All locks held by a transaction are released when a transaction completes.
To properly implement isolation, we use the no-steal eviction policy which guarantees that dirty pages won't be evicted from the buffer pool. If eviction is triggered and all pages in the buffer pool are dirty, the calling transaction will be aborted. When a transaction decides to commit, we always flush its dirty pages to disk to ensure transaction durability. If a transaction decides to abort, we evict its dirty pages from the buffer pool. If the database crashes mid-transaction, the dirty pages in memory will be lost. When the database comes back online, the interrupted transactions that weren’t committed will be lost but the changes made by committed transactions will still be present since they were flushed to disk upon commit.
How to Run
Clone this repository and run the following command to start a SimpleDB REPL that lets you query an example database:
ant
java -jar dist/simpledb.jar parser nsf.schema
Then enter a query into the REPL. For example try:
SELECT g.title FROM grants g WHERE g.title LIKE 'Monkey';
For something more intensive try:
SELECT r2.name, count(g.id)
FROM grants g, researchers r, researchers r2, grant_researchers gr,
grant_researchers gr2
WHERE r.name = 'Samuel Madden' AND gr.researcherid = r.id
AND gr.grantid = g.id AND gr2.researcherid = r2.id
AND gr.grantid = gr2.grantid
GROUP BY r2.name
ORDER BY r2.name;
Closing Thoughts
Implementing a simple database from scratch was very illuminating experience for me. The ACID guarantees always seemed like impossible magic, but now I actually understand how it works. I’ve also seen the Volcano model (i.e. the DBIterator interface) show up a few times on the job so the knowledge I’ve gained from this project has also been useful in practice.
Here are some features that would make SimpleDB more efficient (but less simple):
- Add defragmentation for tuples stored in heap file pages
- Allow for dynamically-sized tuples
- Add support for indexes and clustered indexes
- Add sort-merge join physical operator